ComfyUI × Qwen3-TTSでローカル音声生成【AMD ROCm対応ガイド】
目次
はじめに
Qwen3-TTSはAlibabaが2026年1月に公開したオープンソースのテキスト音声合成モデルです。日本語を含む10言語に対応し、3秒の音声サンプルからの声クローンや、テキストで声をデザインする機能も持っています。Apache 2.0ライセンスで商用利用も可能。
今回はこれをROCm(AMD GPU)環境のComfyUI上で動かすまでの手順をまとめます。結論から言うと、最大のハマりポイントはtransformersのバージョンでした。
環境
ホスト: GMKtec NucBox EVO X1(Ubuntu 24.04)
GPU: AMD Radeon 890M(VRAM 1GB + GTT 24GB)
ComfyUI: Docker(ROCm 7.2)
モデル: Qwen3-TTS-12Hz-1.7B
Docker Compose構成
ComfyUIコンテナの定義は以下のようになっています。
comfyui-amd:
image: rocm/pytorch:rocm7.2_ubuntu24.04_py3.12_pytorch_release_2.9.1
container_name: ai_comfyui-amd
restart: always
ports:
- "8188:8188"
devices:
- "/dev/kfd:/dev/kfd"
- "/dev/dri:/dev/dri"
security_opt:
- seccomp:unconfined
group_add:
- video
- render
volumes:
- ./data:/data
environment:
- HSA_OVERRIDE_GFX_VERSION=${HSA_OVERRIDE_GFX_VERSION}
- COMFYUI_ARGS=${COMFYUI_ARGS}
- PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
working_dir: /data
command: >
sh -c "if [ ! -d 'ComfyUI' ]; then
git clone https://github.com/comfyanonymous/ComfyUI.git;
fi &&
cd ComfyUI &&
if [ ! -d 'custom_nodes/ComfyUI-Manager' ]; then
git clone https://github.com/ltdrdata/ComfyUI-Manager.git custom_nodes/ComfyUI-Manager;
fi &&
pip install -r requirements.txt &&
pip install gitpython toml aiohttp &&
pip install transformers==4.57.3 'huggingface-hub>=0.34.0,<1.0' &&
pip install -r custom_nodes/ComfyUI-Qwen-TTS/requirements.txt --no-deps ||true &&
python main.py --listen 0.0.0.0 --reserve-vram 1 --use-pytorch-cross-attention --disable-pinned-memory"ポイントは command 内で transformers==4.57.3 を明示的にインストールしている点です。理由は後述します。
ComfyUI-Qwen-TTSのインストール
1. カスタムノードのクローン
コンテナ内に入り、カスタムノードをインストールします。
docker exec -it ai_comfyui-amd bash
cd /data/ComfyUI/custom_nodes
git clone https://github.com/flybirdxx/ComfyUI-Qwen-TTS.git2. 依存パッケージのインストール
cd ComfyUI-Qwen-TTS
pip install -r requirements.txtこれにより librosa、soundfile、accelerate、tiktoken、sox、onnxruntime など必要なパッケージがインストールされます。
3. ComfyUIの再起動
exit
docker restart ai_comfyui-amd起動ログでエラーがないか確認します。
docker logs ai_comfyui-amd --since 1m 2>&1 | grep -i "error\|qwen"以下のように表示されれば正常です。
0.2 seconds: /data/ComfyUI/custom_nodes/ComfyUI-Qwen-TTS最大のハマりポイント:transformersのバージョン
問題
ComfyUI-Qwen-TTSの requirements.txt には transformers>=4.57.0 と記載されていますが、ROCm版PyTorchのDockerイメージには transformers==5.5.0 がプリインストールされている場合があります。
transformers 5.x系では以下の非互換が発生し、ノードの読み込みやモデルのロードに失敗します。
エラー | 原因 |
|---|---|
|
|
| RoPE初期化関数から |
| 4.x系には存在しないモジュール(5.x以降で追加) |
| tokenizer内部APIの変更 |
| attention実装の変更による推論時のテンソル形状不一致 |
pad_token_id や ROPE_INIT_FUNCTIONS の問題は個別にパッチを当てることも可能ですが、次々と新しい非互換が見つかり、モグラ叩き状態になります。
解決策
transformers==4.57.3 を使う。これが唯一の安定した解決策です。
Qwen3-TTSの公式パッケージも transformers==4.57.3 を要求しており、この組み合わせが動作保証されています。
pip install transformers==4.57.3 "huggingface-hub>=0.34.0,<1.0"transformers 4.57.x は huggingface-hub<1.0 を要求するため、huggingface-hub も併せてダウングレードする必要があります。
Docker Composeでの恒久対策
コンテナを再起動すると transformers のバージョンがDockerイメージのデフォルトに戻る可能性があります。Docker Composeの command に以下を追加し、起動のたびに正しいバージョンがインストールされるようにします。
pip install transformers==4.57.3 'huggingface-hub>=0.34.0,<1.0' &&
pip install -r custom_nodes/ComfyUI-Qwen-TTS/requirements.txt --no-deps ||true &&--no-deps を付けているのは、Qwen-TTSの requirements.txt が transformers>=4.57.0 と記載しているため、依存解決が走ると transformers が再び5.x系にアップグレードされてしまうのを防ぐためです。
基本的な使い方
CustomVoice(プリセット音声)
最もシンプルな音声生成方法です。9種類のプリセットスピーカーからモデルを選んでテキストを入力するだけ。
ノードを追加 → Qwen3-TTS → CustomVoice
ノードを追加 → オーディオ → オーディオプレビュー
CustomVoiceのAUDIO出力をオーディオプレビューに接続
テキストを入力して生成
CustomVoiceの設定
パラメータ | 説明 | 推奨値 |
|---|---|---|
model_choice | モデルサイズ | 1.7B(高品質)または0.6B(軽量) |
speaker | プリセット音声 | Ono_Anna(日本語向け) |
text | 読み上げるテキスト | 日本語テキスト |
language | 言語 | Japanese |
instruct | 声の指示 | 空欄でもOK |
attention | アテンション方式 | sdpa(AMD環境推奨) |
precision | 精度 | bf16(省メモリ) |
unload_model_after_generate | 生成後にモデルを解放 | 有効(メモリ節約) |
初回実行時に1.7Bモデル(約4.5GB)が自動ダウンロードされるため、しばらく待つ必要があります。
Attention設定のTips
ROCm環境では FlashAttention 2 は使えないため、以下の優先順位で選択されます。
sdpa(PyTorch 2.0+ 標準)— デフォルトでこれが選択されます
eager — sdpaで問題が出る場合のフォールバック
ノードの設定で attention パラメータを変更できます。通常は auto(自動選択)のままで問題ありません。
実際に音声を生成してみた
ワークフローはこんな感じ(念のため、AlekPetの翻訳ノードを入れています)
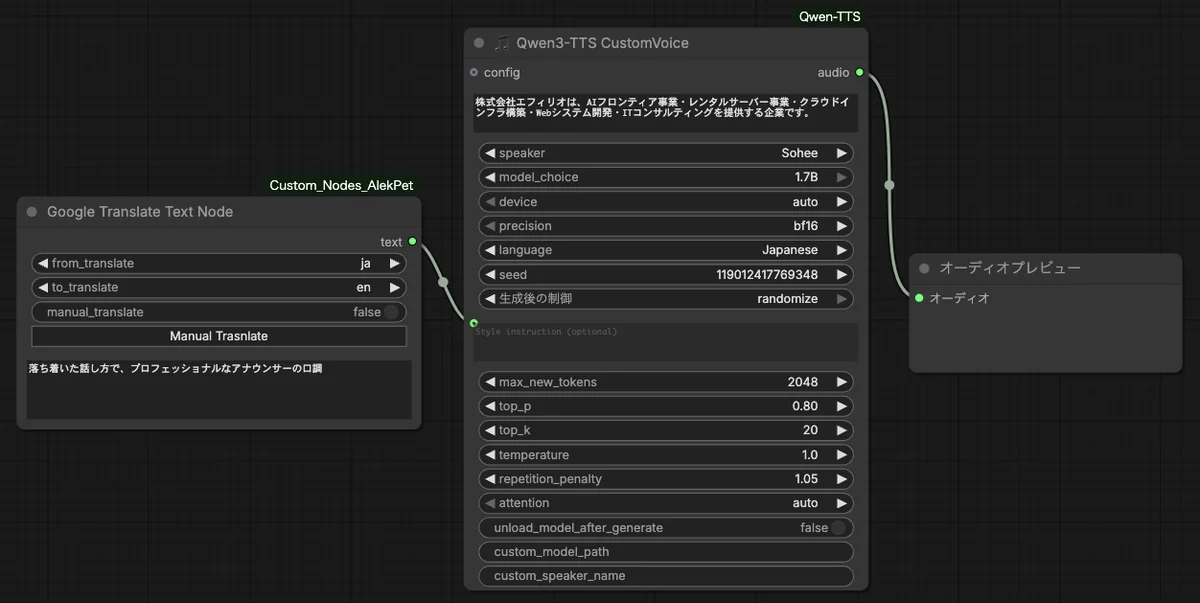
実際に生成した音声
ちょっとイントネーションが不自然なところはあるけど良しとします。
まとめ
ROCm環境でのComfyUI-Qwen-TTSセットアップにおける最大の落とし穴は transformers のバージョン です。5.x系とは多数の非互換があり、個別パッチでの対応は現実的ではありません。transformers==4.57.3 を明示的に固定し、Docker Composeの起動コマンドに含めることで、安定した運用が可能になります。
上流のQwen3-TTSリポジトリでは transformers 5.x対応のPR(#201)が提出されていますが、マージされるまではバージョン固定が推奨です。