ACE-Step 1.5でローカル音楽生成【AMD ROCm Docker導入ガイド】
目次
はじめに
Qwen3-TTSで音声生成ができるようになったので、次は音楽生成を試してみました。ACE-Step 1.5はACE StudioとStepFunが共同開発したオープンソースの音楽生成モデルで、テキストでスタイルや歌詞を指示すると、ボーカル付きの楽曲をまるごと生成してくれます。MITライセンスで商用利用可能。
SunoやUdioのようなクラウドサービスと違い、完全にローカルで動きます。VRAM 4GB未満で動作し、50以上の言語の歌詞に対応。RTX 5090なら数十秒で1曲生成できるとのこと。
今回はこれをROCm環境でDocker Composeを使って動かすまでの手順をまとめます。ハマりポイントは4つありました。nano-vllmのインストール、CUDA版torch依存のスキップ、torchcodecの非対応、そしてMP3/FLAC出力の対応です。
環境
ホスト: GMKtec NucBox EVO X1(Ubuntu 24.04)
GPU: AMD Radeon 890M(VRAM 1GB + GTT 24GB)
Docker Image:
rocm/pytorch:rocm7.2_ubuntu24.04_py3.12_pytorch_release_2.9.1
ディレクトリ構成
~/local_LLMとは別のディレクトリに構築します。ACE-Stepは使うときだけ起動して、普段はOllamaやComfyUIにメモリを譲る運用です。
mkdir -p ~/acestep/data
cd ~/acestepDocker Compose構成
services:
acestep:
image: rocm/pytorch:rocm7.2_ubuntu24.04_py3.12_pytorch_release_2.9.1
container_name: ai_acestep
restart: "no"
ports:
- "7860:7860"
devices:
- "/dev/kfd:/dev/kfd"
- "/dev/dri:/dev/dri"
security_opt:
- seccomp:unconfined
group_add:
- video
- render
ipc: host
volumes:
- ./data:/data
environment:
- HSA_OVERRIDE_GFX_VERSION=${HSA_OVERRIDE_GFX_VERSION}
- MIOPEN_FIND_MODE=FAST
- ACESTEP_LM_BACKEND=pytorch
working_dir: /data
command: >
bash -c "
if [ ! -d 'ACE-Step-1.5' ]; then
git clone https://github.com/ace-step/ACE-Step-1.5.git;
fi &&
cd ACE-Step-1.5 &&
pip install -r requirements-rocm.txt &&
pip install acestep/third_parts/nano-vllm &&
pip install --no-deps -e . &&
pip install audio-separator onnxruntime &&
apt-get update && apt-get install -y ffmpeg &&
acestep --server-name 0.0.0.0 --port 7860 --config_path acestep-v15-turbo --backend pt --language ja --enable-api
".envファイル:
HSA_OVERRIDE_GFX_VERSION=11.5.1Qwen3-TTSの記事と同じROCm PyTorchベースイメージを使っています。audio-separatorとffmpegも一緒に入れているのは、音源分離やMP3変換で必要になるためです。
ハマりポイント①:nano-vllmが見つからない
pip install -e .を実行すると以下のエラーが出ます。
ERROR: Could not find a version that satisfies the requirement nano-vllmnano-vllmはPyPIに公開されておらず、リポジトリ内のacestep/third_parts/nano-vllmにローカルパッケージとして含まれています。先にこれを個別にインストールしておく必要があります。
pip install acestep/third_parts/nano-vllmハマりポイント②:CUDA版torchを要求される
nano-vllmを入れた後でpip install -e .を実行すると、今度は別のエラーが出ます。
ERROR: Could not find a version that satisfies the requirement torch==2.10.0+cu128pyproject.tomlがCUDA版torchを要求しているのが原因です。ROCm版torch(2.9.1+rocm7.2)は既にインストール済みなので、--no-depsで依存解決をスキップします。
pip install --no-deps -e .必要なパッケージはrequirements-rocm.txtで既に入っているので、これで問題ありません。
ハマりポイント③:torchcodecが使えない
起動はできるのですが、音楽を生成するとMP3やFLACの保存段階でエラーが出ます。
ImportError: TorchCodec is required for save_with_torchcodec.ROCm環境のDockerイメージに含まれているtorchaudioは、音声の保存時にtorchcodecを呼び出します。torchcodecはROCm環境では利用できないため、ここで失敗します。
解決策:torchaudio.saveをsoundfileに差し替え
torchaudio.saveを使っている箇所をsoundfileベースの保存処理に差し替えます。
docker exec -it ai_acestep bash
cd /data/ACE-Step-1.5
# バックアップ
cp acestep/audio_utils.py acestep/audio_utils.py.bak
# soundfileでの保存関数をファイル先頭に追加
sed -i '1s/^/import soundfile as sf\nimport numpy as np\ndef _sf_save(filepath, tensor, sample_rate, **kwargs):\n audio = tensor.cpu().numpy()\n if audio.ndim == 2:\n audio = audio.T\n sf.write(str(filepath), audio, sample_rate)\n\n/' acestep/audio_utils.py
# torchaudio.saveを_sf_saveに置換
sed -i 's/torchaudio\.save(/_sf_save(/g' acestep/audio_utils.py
exit
docker restart ai_acestepこの修正でtorchaudioのtorchcodec依存を完全に回避できます。MP3の場合は_sf_saveで一時WAVに保存した後、ffmpegでMP3に変換する既存の処理がそのまま動きます。FLACもWAVも問題なく出力されます。
ハマりポイント④:デフォルトのオーディオフォーマット
③の修正をしない場合の回避策として、UIのオーディオフォーマット設定を「MP3」から「FLAC」に変更するだけでもエラーは回避できます。ただし根本的にはtorchaudio.saveが問題なので、③の修正を行っておくのが確実です。
デフォルト値をFLACに変更したい場合は以下で対応できます。
sed -i 's/params.get("audio_format", "mp3")/params.get("audio_format", "flac")/' \
acestep/ui/gradio/interfaces/generation_advanced_output_controls.py起動手順
OllamaやComfyUIを停止してメモリを確保してから起動します。
cd ~/local_LLM && docker compose stop
cd ~/acestep && docker compose up初回はリポジトリのクローン、依存パッケージのインストール、モデルのダウンロード(数GB)で時間がかかります。ログに以下の表示が出ればGPUが正常に認識されています。
ROCm GPU detected: AMD Radeon Graphics (24.0 GB, HIP 7.2.26015-fc0010cf6a)ブラウザでhttp://[サーバのIPアドレス]:7860にアクセスするとGradio UIが表示されます。
backendの選択肢
--backendオプションは3つあります。
backend | 説明 |
|---|---|
| NVIDIA環境向け。ROCmでは使えない |
| PyTorchバックエンド。AMD環境ではこれ一択 |
| Apple Silicon向け |
環境変数の補足
変数 | 説明 |
|---|---|
| MIOpenのカーネル検索を高速化。これがないとVAE処理でハングすることがある |
| LMバックエンドをPyTorchに固定 |
使い方(簡易)
サービスを初期化ボタンをクリック
キャプション欄に音楽のスタイルを英語で記述(🎲ボタンでランダムサンプルも可)
歌詞欄に歌詞を記述(日本語OK。インスト曲ならInstrumentalチェックをON)
音楽を生成ボタンを押す
キャプションは英語の方が精度が高いです。歌詞は日本語に対応しています。
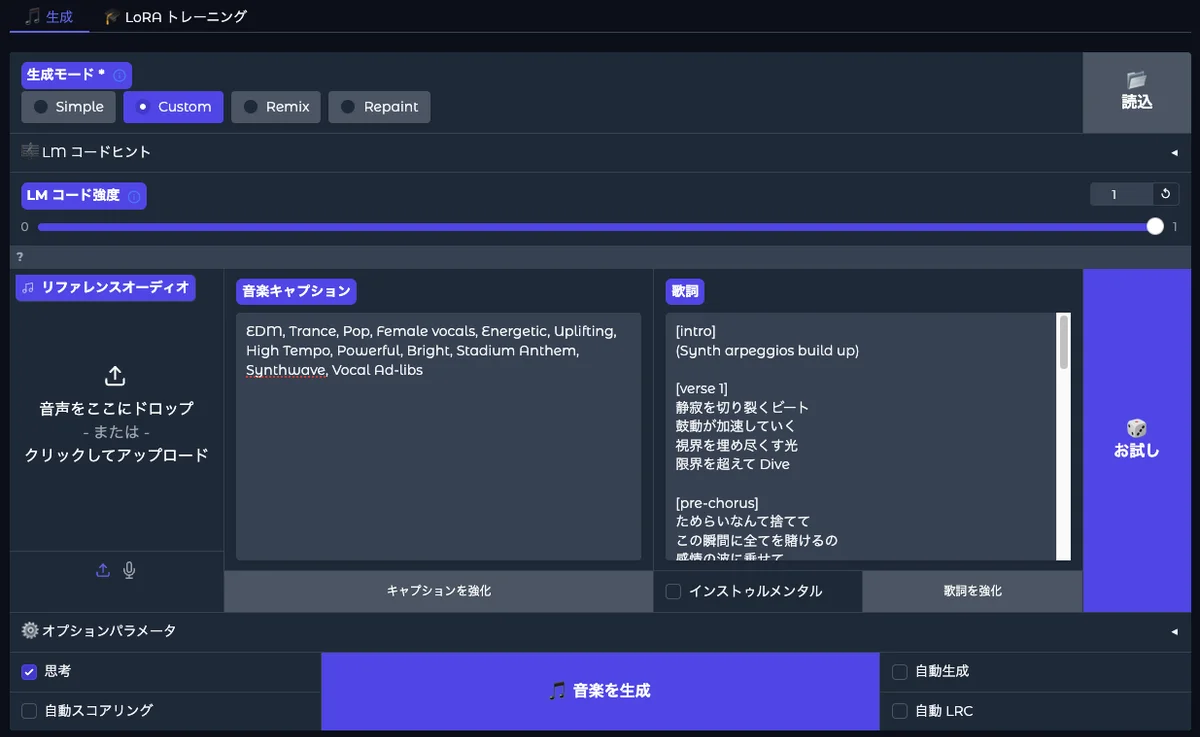
実際に作成した曲がこちら
まとめ
ROCm環境でのACE-Step 1.5は、4つのハマりポイント(nano-vllmのローカルインストール、CUDA版torch依存のスキップ、torchcodecのsoundfile差し替え、オーディオフォーマットのデフォルト値変更)を超えれば安定して動きます。MP3、FLAC、WAVいずれの形式でも出力可能です。
Qwen3-TTSが音声合成、ACE-Stepが音楽生成。ComfyUIで画像、Ollamaでテキスト。Radeon 890MのGTT 24GBでここまでできるようになりました。全部ローカルで動いているのは普通にすごいですよね。


